Message Queue
Message Queue is a type of technique to exchange information in distributed system. MQ can stay in memory or disk until it is being read. In distributed computing system, to achieve effective information exchange, developer needs to build a communication way for asychronous network.
Communication approaches
- Point to point: one2one, one2many, many2many
One message only can be used once, then remove from the queue. - Multiple to multiple
One message can be used multiple times. - Publish/Subscribe:
- Cluster
Kafka
Kafka is a fast, scalable, persistent and highly fault-tolerant distributed publish-subscribe messaging system. Kafka supports high volumn of data and high response in demand better than JMS, RabbitMQ and AMQP. Compared with them, Kafka has higher throughput, more stable and better replication.
It can be used to obtain, analyze and stream processing with Flume, Spark Streaming, Storm, HBase and Flink together. It provides streaming data for Hadoop Big Data Lake. Kafka has low latency in Hadoop and Spark.
Advantages of Kafka
- Reliability
- Scalability
- High performance
Terms
Broker: Server. Kafka cluster contains one or more servers.
Topic: Each message that sends to Kafka cluster has a category, which is called Topic.
Partition: Physical conception; Each topic has one or more partition.
Two strategies: 1. Key Hash algorithm; 2. Round Robin algorithm
Producer: Response to send message to Kafka broker
Consumer: Response to retrieve message from Kafka broker
Consumer Group
Zookeeper: Kafka relies on Zookeeper cluster save metadata for load balancing.
Offset: Index
Architecture
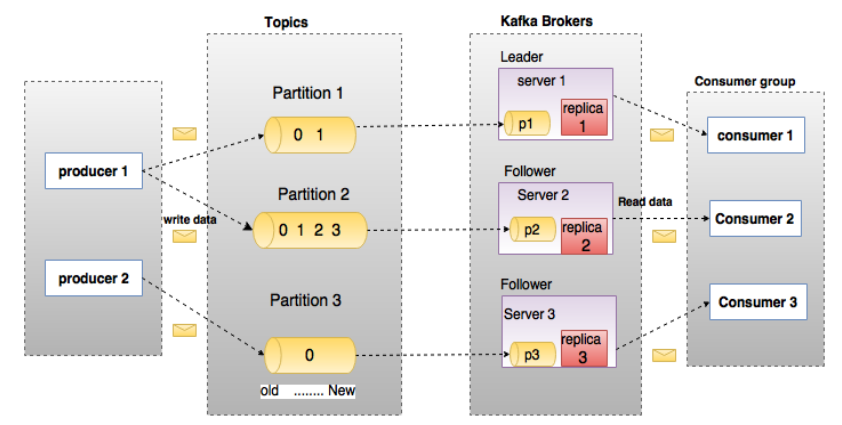
Producers send messages to Brokers;
Leader Broker gets and writes message into target topic to achieve persistency, and sets expire time.
Leader Broker delivers Follow Broker as replication;
Consumers retrieve messages from Brokers
Compare to Flume
1.
Flume is designed to send message to HDFS and HBase.
Kafka is a general-purpose system.
2.
Flume has many sources and sinks, but Kafka doesn’t.
If data source has been determined, just use Flume; Otherwise, adopt Kafka.
- Flume can process data in real-time by intercepter(Filter data)
Kafka needs an external system to help processing. - If data node failed, Flume cannot visit this node until node has been fixed, but it doesn’t happen in Kafka. Because Flume doesn’t have replicalition.
Implements
- Message Queue: enough to rival traditional message system like ActiveMR and RabbitMQ
- Behaviors tracking: Track users’ behaviors from browsing websites and searching. Saving into topic by Publish/Subscribe mode.
- Metadata monitoring: Data monitoring
- Log collecting: Other products like Scribe, Apache Flume.
- Streaming processing: Products like Storm, Samza
- Event source: