Spark is a large-scale data computing engine, which is written by Scala.
Features of Apache Spark
- Faster speed: In memory,theoretically, the speed of Spark is 100 times faster than Speed of Hadoop
- In-memory computing engine: provides Cache mechanism to support continuous iterations or retrieve shared data, reduce cost of I/O of data.
- DAG engine: reduce cost of HDFS Read/Write during computing
- Use multi-threaded pool to reduce cost of task startup.
- Easy to use:
over 80 high-level operators.
supports Java, Python, Scala, R
the amount of code is 2 to 5 times less than MapReduce’s - Generalization: provides many libraries like Spark SQL, Spark MLlib, Spark GraphX, Spark Streaming.
- Supports multiple resource schedulers: Hadoop Yarn, Apache Mesos, and Standalone cluster scheduler.
Resilient Distributed Datasets(RDD) : Key Point
- Collections in cluster, which is read only and consists of Partitions.
- Stores in disk or memory.
- Operations is composed by transformation and action
- Automatically reorganization if it fails.
Features of Transformation and Action
- Different APIs: T: RDD[X]->RDD[Y]; A:RDD[X]->Z(Z is probably a basic data type like array)
- Lazy actions:
Transformation only record RDD transform relation
Action triggers executions of program
Spark Streaming
Splits streaming data into small pieces and processes batch data. It will reduce latency.
Difference between MR and Spark
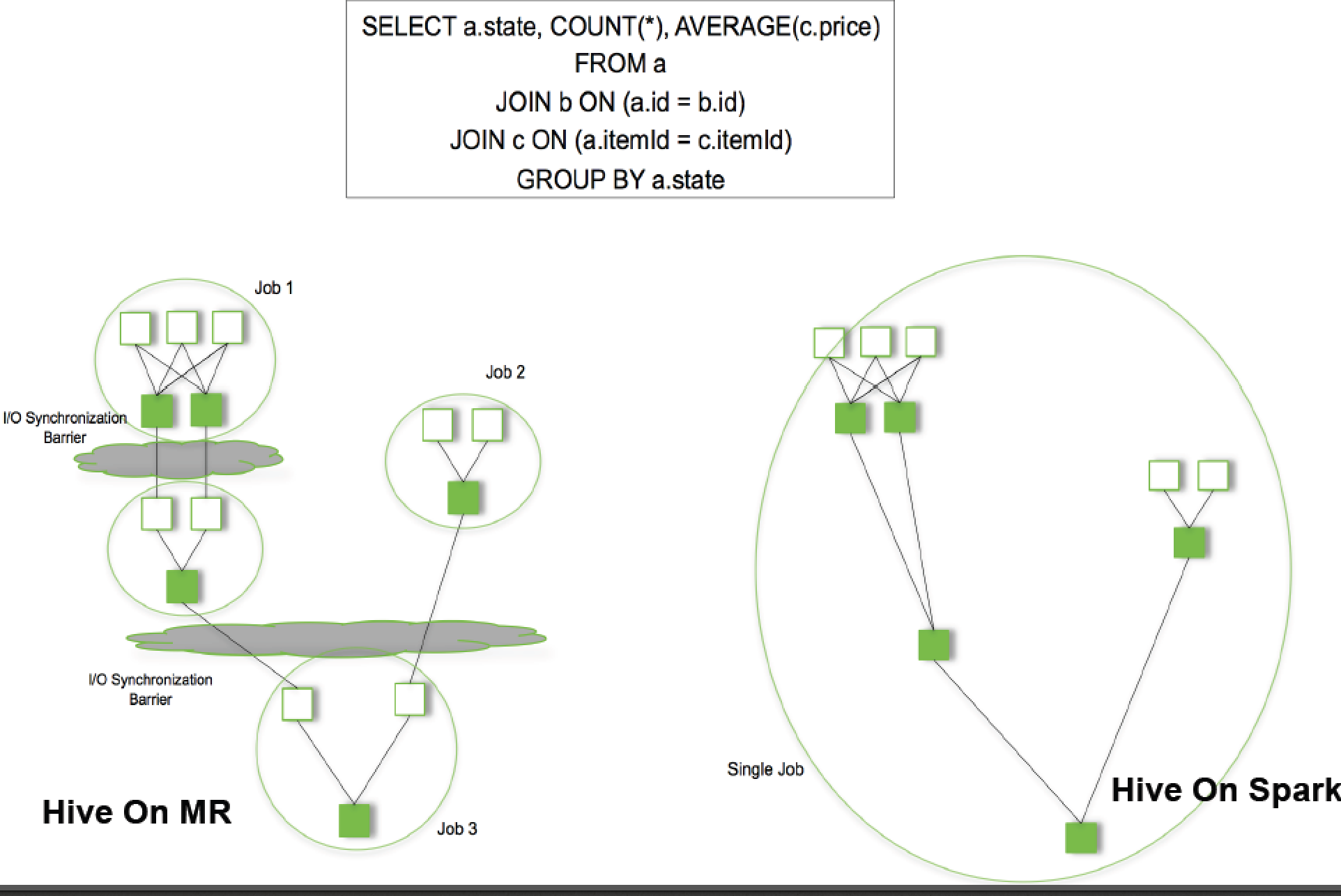
MR:
- Only privides Map and Reduce operations
- Low efficiency of processing: bad at iterating computing, interface processing, and log analysis
- The middle result of Map needs to write into disk and Reduce needs to write into HDFS.
- High cost of Task Scheduling and Startups.
- Cannot fully use of memory
- Map and Reduce need to sort data.
Implements of Spark
- Log collecting and searching
- User’s tap prediction
- Common friends
- ETL task of SparkSQL and DAG