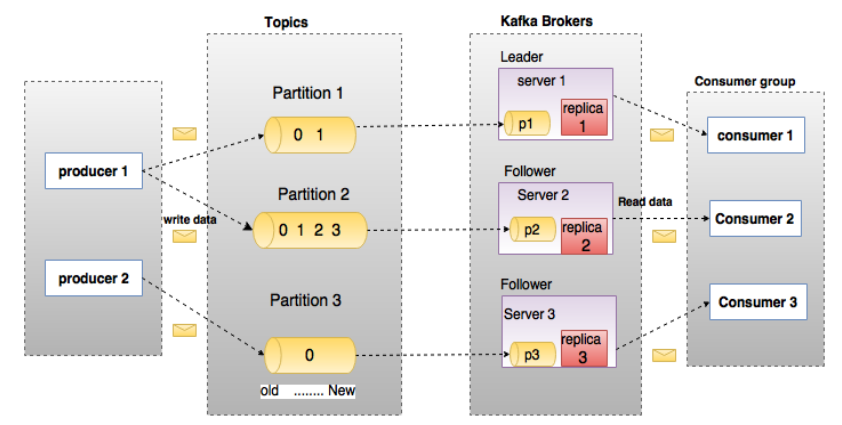
NoSQL database
RDBMS features: ACID
A: Atomicity
C: Consistency
I: Isolation
D: Durability
NoSQL is used to store super large scale data. These data doesn’t need a fix pattern, just scale out.
Distributed system CAP theorem: it cann’t be satisfied three of them at the same time.
Consistency: all nodes has same data at the same time
Availability: guarantee response no matter success or fail
Partition tolerance: system keep operating even part information lost.
Categories
Column-based:
-HBase, Cassandra;
-Easy to compress data; fast-search for a certain column.
Document-based:
-MongoDB, CouchDB
-Storage Format is similar to JSON(K/V Pair), Content is document format.
Key-Value:
-Redis, Memcache
-Search value through key no matter the type of value
Column-oriented
Traditional relational database is row-oriented. Each row has a row id and every field store in one table.
When searching in row-oriented database, each row will be traversed, no matter a certain column data is needed or not. If you search a person whose birth month is September. Search row by row to target data.
Index the target column can promote search speed, but index each column cause extra overload and databse will traverse all columns to search data.
Column-oriented database will stores each column seperately. It’s very fast to search when the data amount is small. Search column by column to targetdata.
This design looks like adding index for each row. It sacrifices space and writing more index to speed up searching ability. Index maps row ID to data, but column-based database maps data to rowID. Like the picture above, it is easy to search who like archery. This is an inverted index.
When to use row-oriented and when to use column-oriented? Column-based database is easy to add one new column, but is difficult to add one row. Therefore, row-oriented database is bettern than column-based on transaction. Because it achieves real-time update. It is commonly used in marketing business.
Column-oriented database has advantage of data analysis, like sum of values. Batch processing can adopt column-oriented database at night, and it supports quick search and MapReduce aggregation.
Compared to RDBMS
If you want to get all infomation of one user, column-based database costs more;
If you want to get one piece of information of one user, row-based database costs more.
Row-based is faster than Column-based on Updating a target row;
Column-based is faster than Row-based on Searching part of information of users;
Row-based database: OLTP
Column-based database: OLAP
K/V stores
This is the easiest store in NoSQL databases.
the complex k/v paire is like:
Document-oriented stores
Store based on K/V pair, but structure more complex.
MongoDB
Written in C++
Remains some friendly properties of SQL.(Query, index)
Support secondary index
Master-slave replication
Queries support javascript expressions
Better update-in-place than CouchDB
Sharding built-in
Uses memory mapped files for data storage
After crash, it needs to repair tables
Reads faster than wirtes
Use: need dynamic search. Dedine indexes first, no need map/reduce.
Example: Adapts all situations of MySQL and PostgreSQL
Cassandra
Written in Java
Querying by column
Writes are much faster than reads
Column-based databse.
Weak consistency; High availability; High scalability
Use: adapts to implement in write action more than read action
Example: Logging system, Banking system, Finance system.
HBase
Written in Java
Billion row level and Million column level
Map/Reduce with Hadoop
Store in HDFS
No single point of failure
Strong consistency; Low availability; High scalability
Use: Big table, random and real-time read/write action
Example: Facebook message database
Redis
Written in c/c++
Blazing fast
Disk-backed in-memory database
Master-slave replication
Store as key/value format
Support set, list, hash
Has transactions
Value can be set to expire
Publish/Subscribe and Watch
Use: if data is not huge and changes frequently, store in Redis. Fast read/write data
Example: Stock price analysis, Real-time data processing